Instance Matching or Link Discovery
The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of Web resources across knowledge bases. In most cases, the cross-dataset links are not explicit in the dataset and must be automatically determined using Instance Matching (IM) and Link Discovery tools amongst others. The large variety of techniques requires their comparative evaluation to determine which one is best suited for a given context. Performing such an assessment generally requires well-defined and widely accepted benchmarks to determine the weak and strong points of the proposed techniques and/or tools.
A number of real and synthetic benchmarks that address different data linking challenges have been proposed for evaluating the performance of such systems. So far, only a limited number of link discovery benchmarks target the problem of linking geo-spatial entities. However, some of the largest knowledge bases on the Linked Open Data Web are geospatial knowledge bases (e.g., LinkedGeoData with more than 30 billion triples). Linking spatial resources requires techniques that differ from the classical mostly string-based approaches. In particular, considering the topology of the spatial resources and the topological relations between them is of central importance to systems driven by spatial data.
We believe that due to the large amount of available geospatial datasets employed in Linked Data and in several domains, it is critical that benchmarks for geospatial link discovery are developed.
The proposed Task entitled “Instance Matching or Link Discovery Task” is presented at the OAEI OM 2021 Workshop at ISWC 2021. OM workshop conducts an extensive and rigorous evaluation of ontology matching and instance matching (link discovery) approaches through the OAEI (Ontology Alignment Evaluation Initiative) 2021 campaign.
Tasks and Training Data
The aim of the Task is to test the performance of Link Discovery tools that implement string-based as well as topological approaches for identifying matching instances and spatial entities. The different frameworks will be evaluated for both accuracy (precision, recall and f-measure) and time performance.
SPIMBENCH
The goal of the SPIMBENCH task is to determine when two instances describe the same Creative Work. A dataset is composed of a Tbox (contains the ontology and the instances) and corresponding Abox (contains only the instances). The datasets share almost the same ontology (with some difference in the properties’ level, due to the structure-based transformations). What we expect from participants. Participants are requested to match instances in the source dataset (Tbox1) against the instances of the target dataset (Tbox2). The task goal is to produce a set of mappings between the pairs of matching instances that are found to refer to the same real-world entity. An instance in the source (Tbox1) dataset can have none or one matching counterparts in the target dataset (Tbox2). We ask the participants to map only instances of Creative Works (http://www.bbc.co.uk/ontologies/creativework/NewsItem, http://www.bbc.co.uk/ontologies/creativework/BlogPost and http://www.bbc.co.uk/ontologies/creativework/Programme) and not the instances of the other classes.
You can download training data here: SPIMBENCH training data
Spatial
We use the TomTom and Spaten datasets in order to create the appropriate benchmarks.
TomTom provides a Synthetic Trace Generator developed in the context of the HOBBIT Project, that facilitates the creation of an arbitrary volume of data from statistical descriptions of vehicle traffic. More specifically, it generates traces, with a trace being a list of (longitude, latitude) pairs recorded by one device (phone, car, etc.) throughout one day. TomTom was the only data generator in the first version of SPgen. Spaten is an open-source configurable spatio-temporal and textual dataset generator, that can produce large volumes of data based on realistic user behavior. Spaten extracts GPS traces from realistic routes utilizing the Google Maps API, and combines them with real POIs and relevant user comments crawled from TripAdvisor. Spaten publicly offers GB-size datasets with millions of check-ins and GPS traces. This version of the challenge will comprise the Spatial task that measures how well the systems can identify DE-9IM (Dimensionally Extended nine-Intersection Model) topological relations [2]. The supported spatial relations are the following: Equals, Disjoint, Touches, Contains/Within, Covers/CoveredBy, Intersects, Crosses, Overlaps and the traces are represented in Well-known text (WKT) format. For each relation, a different pair of source and target dataset will be given to the participants. The Spatial Benchmark generator (Task 2) can be used to test the performance of systems that deal with topological relations proposed in the state of the art DE-9IM (Dimensionally Extended nine-Intersection Model) model [3]. This benchmark generator implements all topological relations of DE-9IM between trajectories in the two dimensional space. To the best of our knowledge such a generic benchmark, that takes as input trajectories and checks the performance of linking systems for spatial data does not exist. For the design, we focused on (a) on the correct implementation of all the topological relations of the DE-9IM topological model and (b) on producing large datasets large enough to stress the systems under test. The supported relations are: Equals, Disjoint, Touches, Contains/Within, Covers/CoveredBy, Intersects, Crosses, Overlaps.
Spatial task consists of two subtasks:
-
Task 2.1 : TomTom dataset
-
2.1.1 : Match LineStrings to LineString
-
2.1.2 : Match LineStrings to Polygons
-
-
Task 2.2 : Spaten dataset
-
2.2.1 : Match LineStrings to LineString
-
2.2.2 : Match LineStrings to Polygons
-
The namespaces of the datasets are:
- TomTom http://www.tomtom.com/ontologies/traces# for the Traces (LineStrings) and the namespace http://www.tomtom.com/ontologies/regions# for the Regions (Polygons)
- Spaten http://www.spaten.com/ontologies/traces# for the Traces (LineStrings) and the namespace http://www.spaten.com/ontologies/regions# for the Regions (Polygons)
You can download training data here: Spatial training data
Systems
| Tool | Institution | Country | Contact person(s) | Task to participate |
|---|---|---|---|---|
| An Efficient System for Matching Large Ontologies (Lily) | Southeast University | China | Peng Wang, Yunyan Hu, Shiyi Zou | SPIMBENCH |
| LogMap | City, University of London | UK | Ernesto Jimenez-Ruiz | SPIMBENCH |
| AgreementMakerLight (AML) | University of Lisbon / Instituto Gulbenkian de Ciencia / University of Illinois at Chicago | Portugal / USA | Daniel Faria, Catia Pesquita | SPIMBENCH, Spatial |
| Distributed Spatial JedAI (DS-JedAI) | National and Kapodistrian University of Athens | Greece | Georgios Mandilaras | Spatial |
| Rapid Discovery of Topological Relations (RADON) | AKSW | Germany | Mohamed Ahmed Sherif, Kevin Dreßler | Spatial |
| Silk | National and Kapodistrian University of Athens | Greece | Despina Athanasia Pantazi, Panayiotis Smeros | Spatial |
Results
SPIMBENCH
| SANDBOX (~380 instances, ~10000 triples) | |||
|---|---|---|---|
| System | LogMap-HOBBIT | AgreementMakerLight-Hobbit | Lily_HOBBIT-2.2 |
| Fmeasure | 0.841328413 | 0.864516129 | 0.991708126 |
| Precision | 0.938271605 | 0.834890966 | 0.983552632 |
| Recall | 0.762541806 | 0.89632107 | 1 |
| timePerformance | 5699 | 7966 | 1845 |
| MAINBOX (~1800 instances, ~50000 triples) | |||
|---|---|---|---|
| System | LogMap-HOBBIT | AgreementMakerLight-Hobbit | Lily_HOBBIT-2.2 |
| Fmeasure | 0.785635764 | 0.860457622 | 0.995388669 |
| Precision | 0.880131363 | 0.838567839 | 0.990819672 |
| Recall | 0.709463931 | 0.883520847 | 1 |
| timePerformance | 27140 | 46517 | 3458 |
The results can be found in HOBBIT platform: here (login as guest).
Spatial
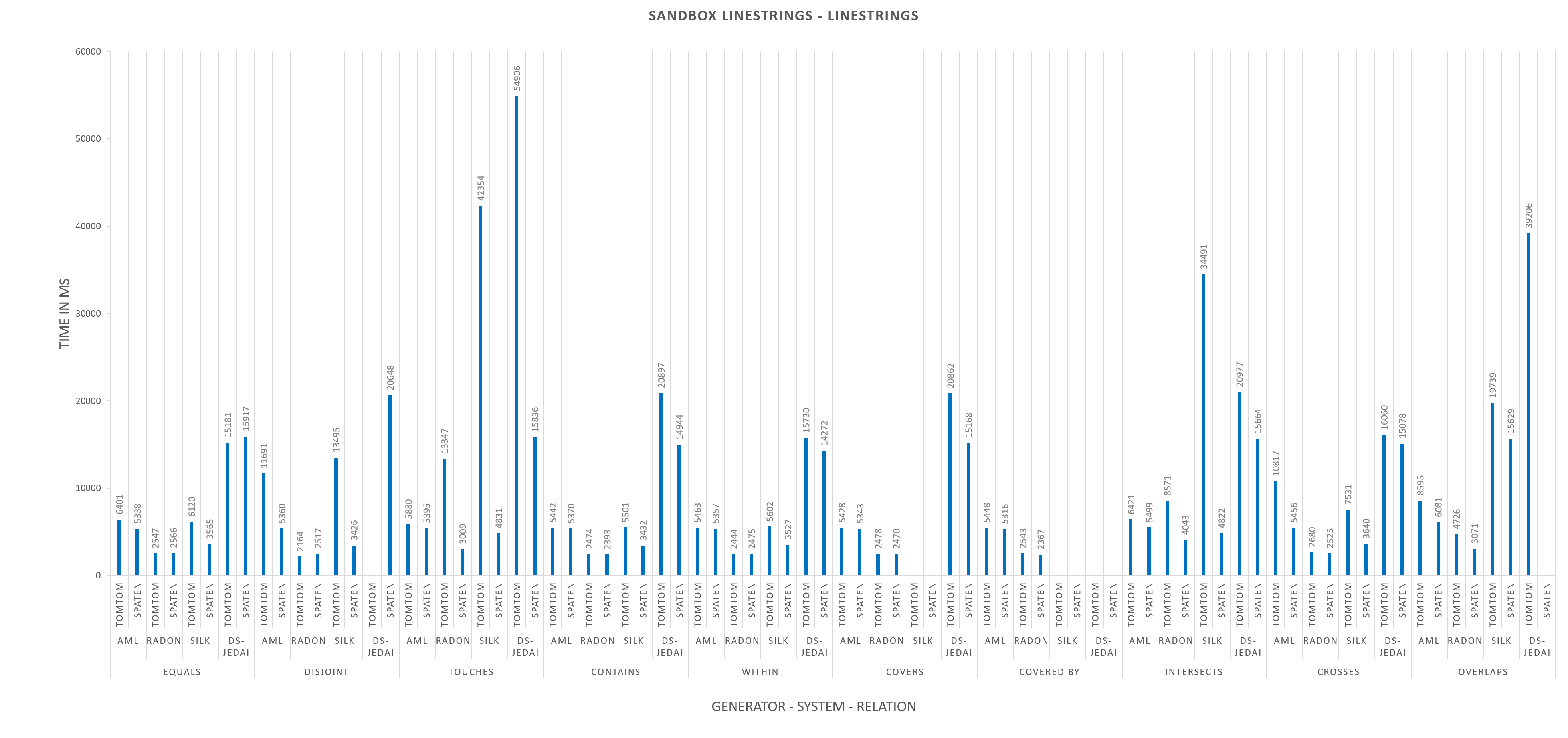
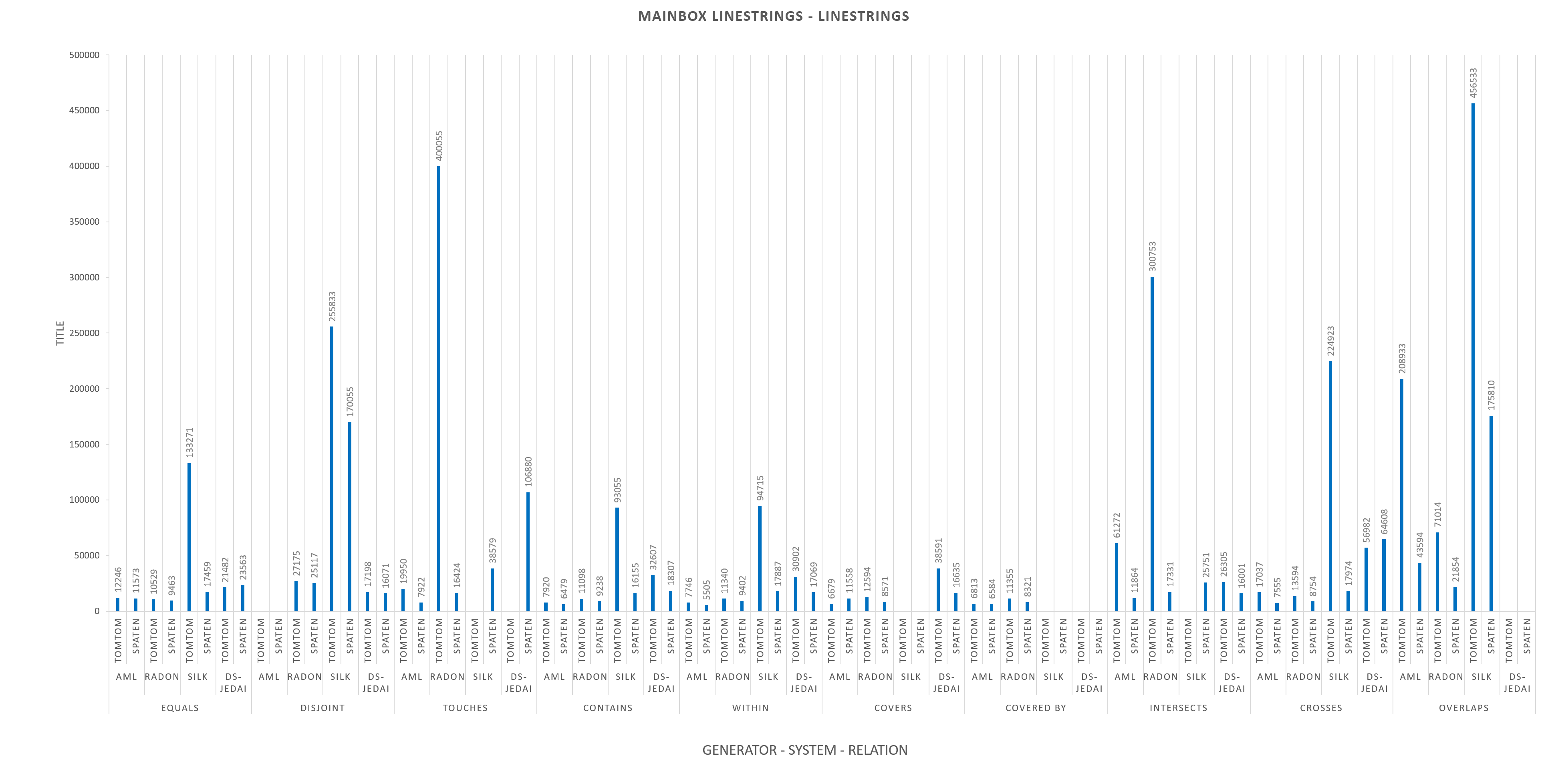
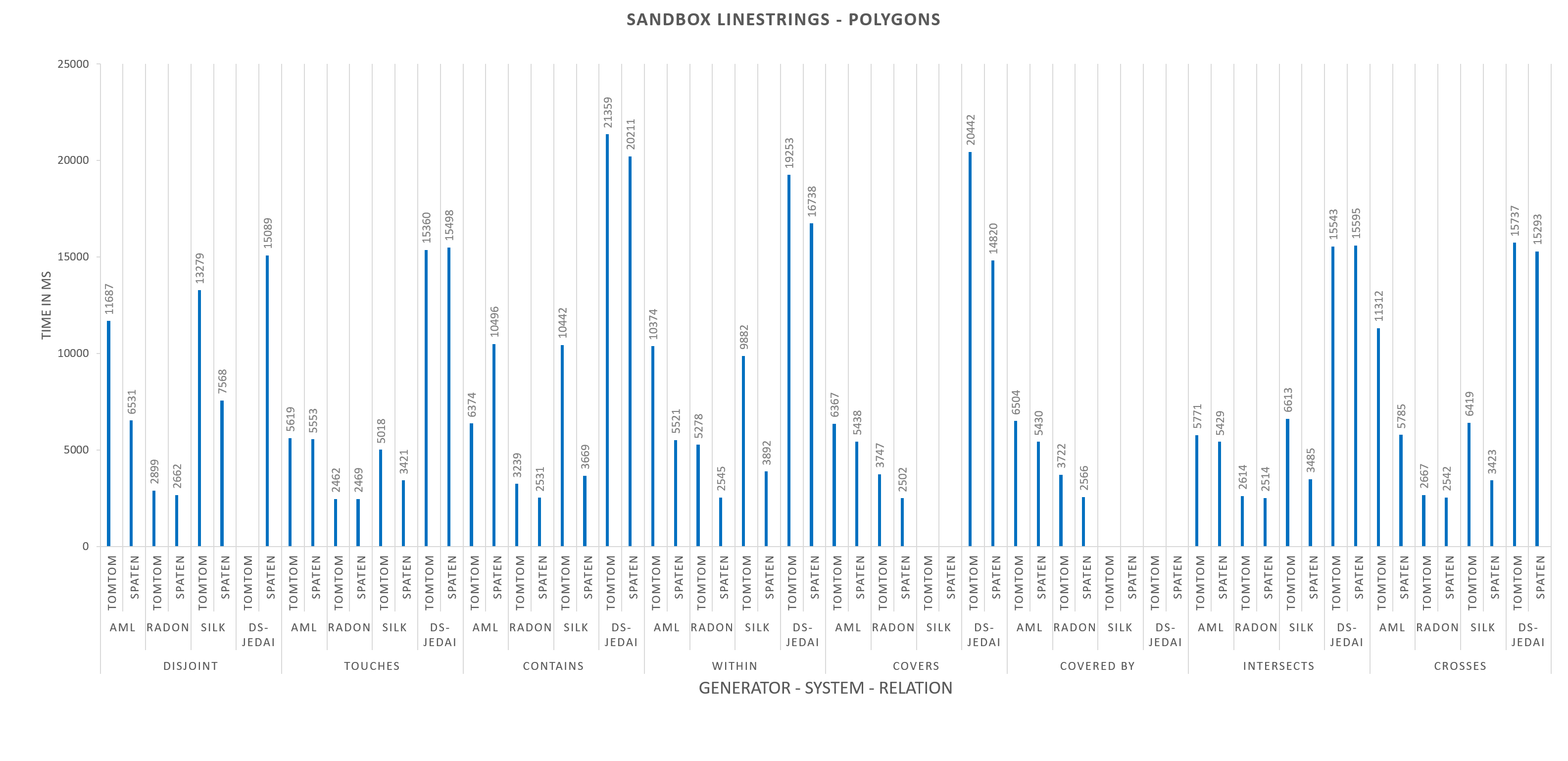
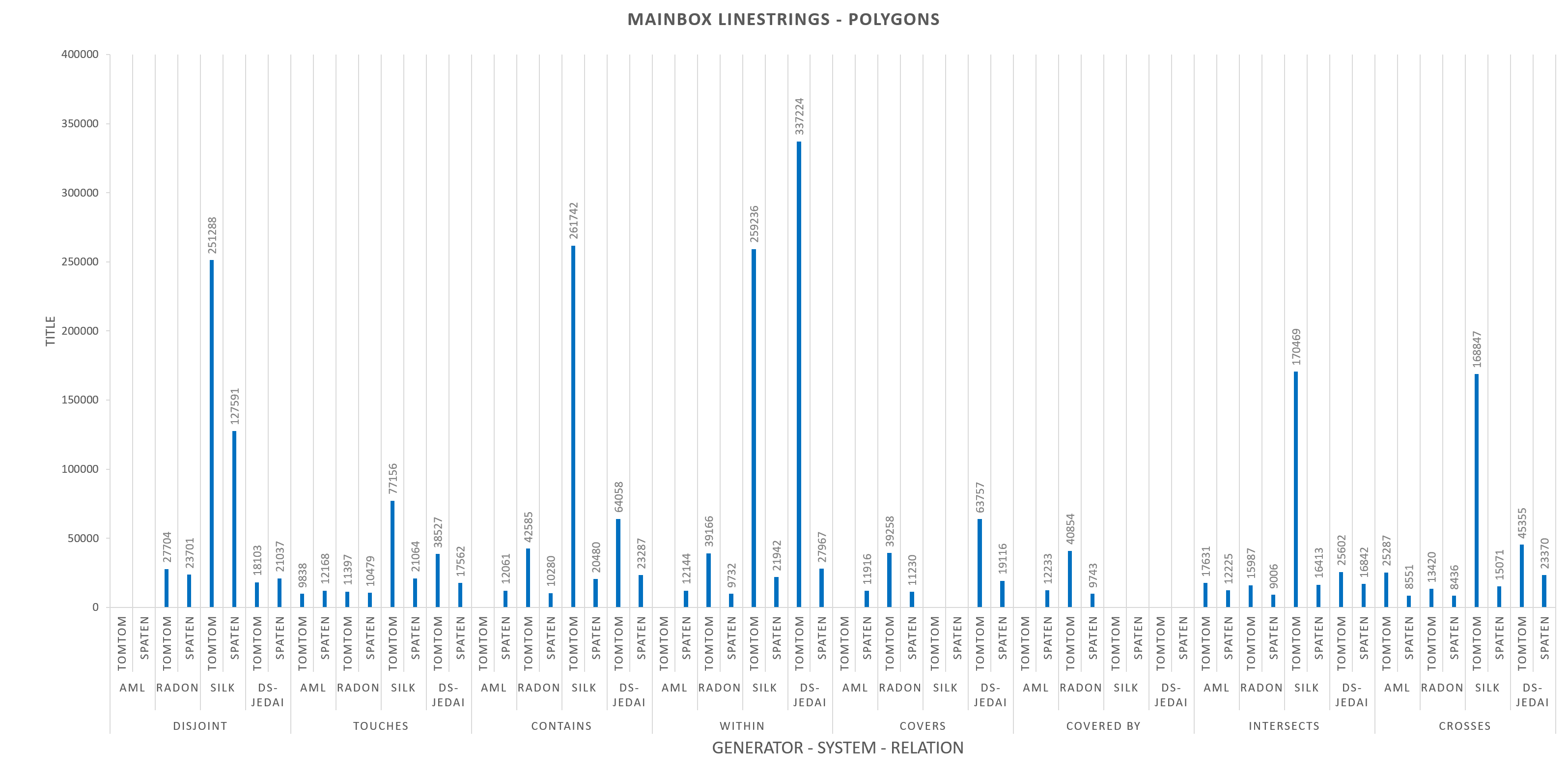
Silk and GS-JedAI do not participate for COVERED BY and Silk does not participate also for COVERS.
In order to make the diagrams more comprehensible we have excluded the extreme values. The excluded values are:
-
Task 2.2 : Spaten dataset, 2.2.1 : Match LineStrings to LineString (Sandbox):
relation: OVERLAPS, System: DS-JedAI, time performance: 724692 ms
-
Task 2.1 : TomTom dataset, 2.1.1 : Match LineStrings to LineString (Mainbox):
relation: TOUCHES, System: Silk, time performance: 2023852 ms
relation: TOUCHES, System: DS-JedAI, time performance: 3533541 ms
relation: INTERSECTS, System: Silk, time performance: 1602288 ms
relation: OVERLAPS, System: DS-JedAI, time performance: 949542 ms
-
Task 2.1 : TomTom dataset, 2.1.2 : Match LineStrings to Polygons (Mainbox):
relation: CONTAINS, System: AML, time performance: 2582081 ms
relation: WITHIN, System: AML, time performance: 2578691 ms
relation: COVERS, System: AML, time performance: 2564912 ms
relation: COVERED BY, System: AML, time performance: 2602657 ms
If a result is empty but does not belong to one of the previous cases then the system has not been able to complete the specific task. The results can be found in HOBBIT platform: here (login as guest).
Organizing Committee:
- Pavel Shvaiko (Main contact) Trentino Digitale, Italy E-mail: pavel [dot] shvaiko [at] tndigit [dot] it
- Jérôme Euzenat INRIA & Univ. Grenoble Alpes, France
- Ernesto Jiménez-Ruiz City, Univeristy of London, UK & SIRIUS, Univeristy of Oslo, Norway Oktie Hassanzadeh IBM Research, USA
- Cássia Trojahn IRIT, France
Program Committee:
- Alsayed Algergawy, Jena University, Germany
- Manuel Atencia, INRIA & Univ. Grenoble Alpes, France
- Zohra Bellahsene, LIRMM, France
- Jiaoyan Chen, University of Oxford, UK
- Valerie Cross, Miami University, USA
- Jérôme David, University Grenoble Alpes & INRIA, France
- Gayo Diallo, University of Bordeaux, France
- Daniel Faria, Instituto Gulbenkian de Ciéncia, Portugal
- Alfio Ferrara, University of Milan, Italy
- Marko Gulić, University of Rijeka, Croatia
- Wei Hu, Nanjing University, China
- Ryutaro Ichise, National Institute of Informatics, Japan
- Antoine Isaac, Vrije Universiteit Amsterdam & Europeana, Netherlands
- Naouel Karam, Fraunhofer, Germany
- Prodromos Kolyvakis, EPFL, Switzerland
- Patrick Lambrix, Linköpings Universitet, Sweden
- Oliver Lehmberg, University of Mannheim, Germany
- Fiona McNeill, Heriot Watt University, UK
- Majid Mohammadi, Eindhoven University of Technology, Netherlands
- Axel Ngonga, University of Paderborn, Germany
- George Papadakis, University of Athens, Greece
- Catia Pesquita, University of Lisbon, Portugal
- Henry Rosales-Méndez, University of Chile, Chile
- Kavitha Srinivas, IBM, USA
- Pedro Szekely, University of Southern California, USA
- Valentina Tamma, University of Liverpool, UK
- Ludger van Elst, DFKI, Germany
- Xingsi Xue, Fujian University of Technology, China
- Ondřej Zamazal, Prague University of Economics, Czech Republic
- Songmao Zhang, Chinese Academy of Sciences, China
Acknowledgements:
We appreciate support from the Trentino as a Lab initiative of the European Network of the Living Labs at Trentino Digitale, the EU SEALS project, as well as the Pistoia Alliance Ontologies Mapping project and IBM Research.
Contact
For more information send an e-mail to: Tzanina Saveta (jsaveta@ics.forth.gr) and Irini Fundulaki (fundul@ics.forth.gr).
References
[1] Saveta, E. Daskalaki, G. Flouris, I. Fundulaki, and A. Ngonga-Ngomo. LANCE: Piercing to the Heart of Instance Matching Tools. In ISWC, 2015.
[2] Christian Strobl. Encyclopedia of GIS , chapter Dimensionally Extended Nine-Intersection Model (DE-9IM), pages 240245. Springer, 2008.